
LinkedIn is quietly rebuilding one of the largest recommendation systems in the world. The platform’s Feed now serves more than 1.3 billion professionals, each navigating their own career journey, learning from industry conversations, and sharing expertise with others. While LinkedIn’s Feed has relied on artificial intelligence for years, recent advances in large language models have allowed the company to rethink how professional content is discovered and distributed.
The result is a new generation of ranking systems powered by large language models, transformer architectures, and GPU-accelerated infrastructure designed to better understand what a post is actually about and how it relates to a member’s evolving professional interests. Behind the scenes, the Feed evaluates millions of posts every time someone opens LinkedIn, balancing network activity, recommended content, and global conversations across the platform.
The system relies on a combination of profile signals and behavioral patterns to determine what users see. These signals include both static information about who a member is professionally and dynamic information about how they interact with content.
Key signals include:
• Profile data such as industry, skills, experience, and location
• Historical engagement signals including likes, comments, shares, and dwell time
• Topics users repeatedly engage with or skip
• How engagement patterns change over time
All of this information is processed within milliseconds to generate a personalized Feed for every user.
From Multiple Systems to a Unified AI Retrieval Engine
For years, LinkedIn relied on several independent systems to retrieve candidate posts for the Feed. These included trending content modules, collaborative filtering models, keyword-based retrieval, and embedding systems designed to match topics.
While effective, this multi-system architecture created engineering complexity and made it difficult to optimize the Feed holistically. LinkedIn has now moved toward a unified retrieval system powered by large language model embeddings, replacing multiple pipelines with a single AI representation of both members and content.

This system allows LinkedIn to understand semantic relationships between professional topics, rather than relying primarily on keyword matches. For example, someone interested in electrical engineering who interacts with posts about small modular reactors might also see content about:
• power grid optimization
• renewable energy infrastructure
• nuclear energy technology
Traditional keyword systems might miss these connections, but LLM-based retrieval can identify conceptual links between topics using world knowledge learned during model training.
This approach is especially powerful in cold-start scenarios, when a new member joins LinkedIn with limited engagement history. By analyzing profile signals such as job title, skills, and industry, the model can infer relevant interests and recommend useful content immediately.
Turning Profiles and Posts Into AI Signals
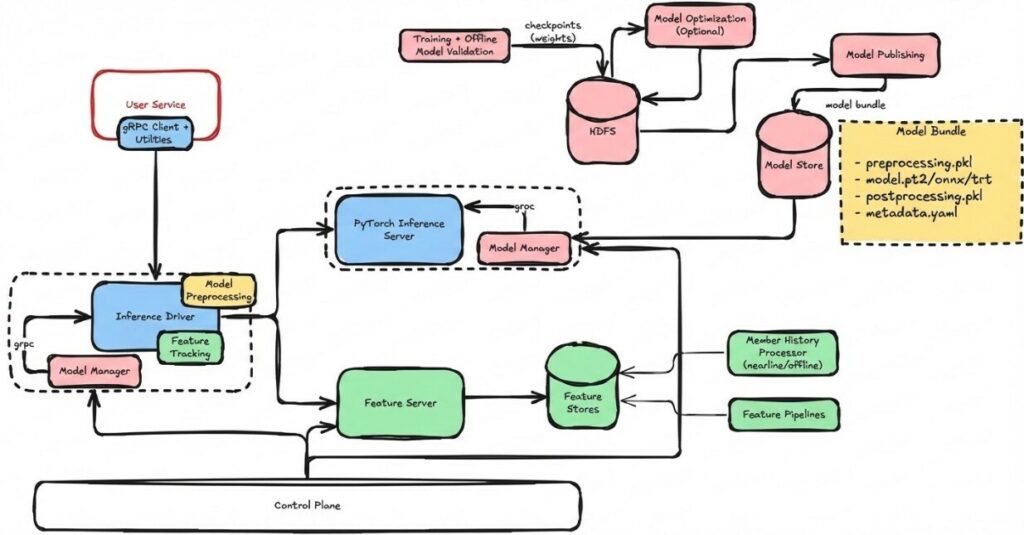
To make large language models work inside a recommendation system, LinkedIn had to translate structured platform data into formats that AI models could interpret. Engineers built what they call a prompt library, a system that converts structured information about posts and members into textual prompts that can be processed by LLMs.
For posts, these prompts may include:
• Author name, headline, company, and industry
• Engagement statistics such as views or interactions
• Article metadata and post text
• Format indicators (video, article, text post)
For members, prompts combine professional signals such as:
• Work history and education
• Skills and industry context
• Profile headline and role
• A chronological sequence of previously engaged posts
One of the most surprising engineering findings involved how large language models interpret numbers. When raw engagement counts were passed directly into the model, they were treated like arbitrary tokens and produced almost no meaningful correlation with relevance signals. Initially, engineers observed a −0.004 correlation between popularity counts and recommendation relevance.
To solve this, LinkedIn converted engagement metrics into percentile buckets. Instead of feeding a model the number “12,345 views,” the system might encode the post as belonging to the 71st percentile of view counts. This simple change produced major improvements:
• 30× stronger correlation between popularity signals and embedding similarity
• 15% improvement in Recall@10, meaning the system retrieved more relevant posts
The result was a more reliable interpretation of engagement signals within the recommendation models.
Training AI Models to Understand Professional Behavior
LinkedIn trained its retrieval models using millions of member-to-content engagement pairs. The architecture uses a dual encoder system, where both members and posts are converted into embeddings within the same vector space. The similarity between those embeddings determines how relevant a piece of content may be for a particular member. During training, the models compare positive engagement examples with negative samples to learn what makes content relevant.
Two types of negatives are used:
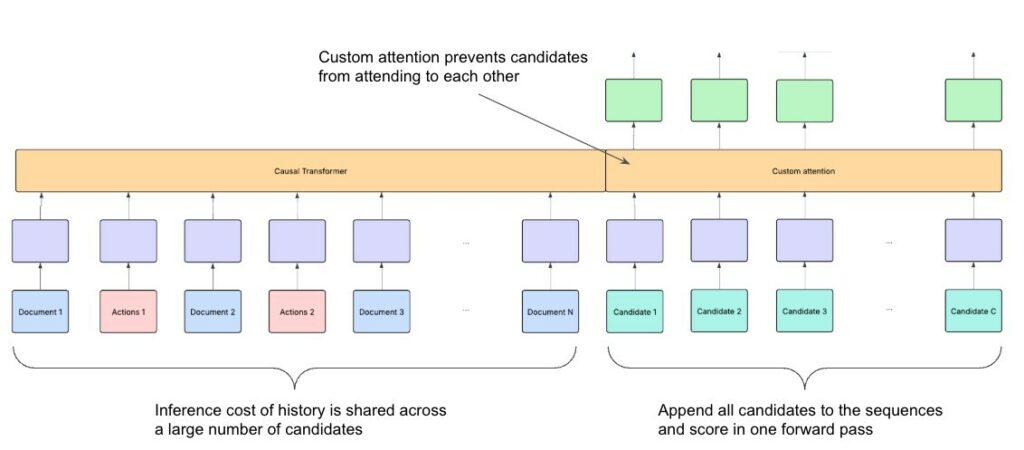
• Easy negatives – randomly sampled posts the member never saw
• Hard negatives – posts shown to the member but ignored
Introducing hard negatives significantly improved model performance:
| Training configuration | Improvement in Recall@10 |
|---|---|
| Easy negatives only | Baseline |
| Easy + 1 hard negative | +2.0% |
| Easy + 2 hard negatives | +3.6% |
Engineers also discovered that training models using only positively engaged posts produced better results than including all impressions. This adjustment improved both model quality and efficiency. Key improvements included:
• 37% reduction in memory footprint
• 40% more training sequences per batch
• 2.6× faster training iterations
These efficiency gains allowed LinkedIn’s teams to experiment with more advanced recommendation strategies.
Understanding the Professional Journey
Retrieval is only the first stage of the Feed pipeline. The next step is ranking the candidate posts to determine what actually appears in a user’s Feed. Traditional recommendation models treat each impression independently, predicting engagement for one post at a time. LinkedIn’s new system takes a different approach by analyzing sequences of user behavior across time.
The platform introduced a Generative Recommender model, which processes more than 1,000 historical interactions to understand how a member’s interests evolve.
Instead of evaluating isolated signals, the model interprets interactions as part of a broader professional learning trajectory. For example, if a user engages with posts about machine learning on Monday, distributed systems on Tuesday, and cybersecurity later in the week, the model may infer an emerging interest in infrastructure security.
This sequential analysis allows LinkedIn to recommend content that reflects where a user’s interests are heading, not just what they interacted with previously.
Engineering the Feed at Global Scale
Deploying transformer-based recommendation models at LinkedIn’s scale required significant infrastructure innovation. Traditional ranking models ran efficiently on CPUs, but transformer architectures require GPU acceleration and high-bandwidth memory to operate effectively.
“We’re rolling out a new advanced ranking system powered by LLMs and GPUs that better understands what a post is actually about and how it relates to a member’s evolving interests and career goals.”
– Hristo Danchev, LinkedIn Engineering
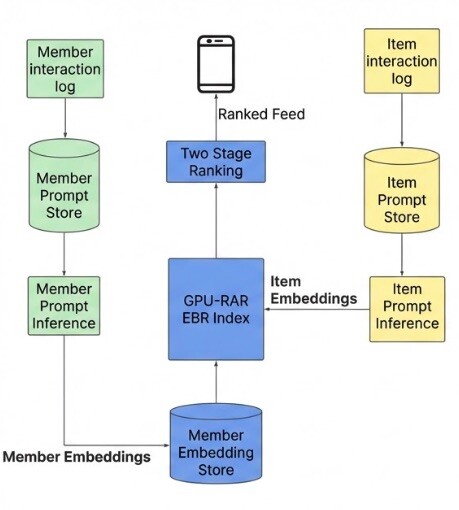
LinkedIn built a distributed architecture that separates CPU-based feature processing from GPU-heavy inference workloads. The system relies on several near-real-time pipelines that continuously update:
• prompt generation from new posts and profile updates
• embedding generation through GPU inference servers
• GPU-accelerated indexes used for nearest-neighbor search
This architecture allows LinkedIn to retrieve relevant content from millions of posts in under 50 milliseconds, while maintaining sub-second response times for Feed generation.
The system continuously refreshes its understanding of both content and members. When a post begins gaining engagement, its embedding is updated within minutes. When users start interacting with new topics, their member embeddings evolve accordingly.
A Smarter Feed for Professional Discovery
The impact of these changes is subtle but significant. The Feed increasingly adapts to professional exploration rather than static preferences. Trending industry discussions can appear within minutes, and emerging interests are reflected quickly in subsequent recommendations.
Professionals may discover relevant insights from creators they do not follow, or encounter perspectives expressed in different terminology than they typically use. By understanding deeper semantic relationships between topics and tracking evolving engagement patterns, LinkedIn’s recommendation systems expand access to professional knowledge across the platform.
LinkedIn’s next-generation Feed represents more than an algorithm update. It reflects a fundamental shift in how professional information is distributed and discovered. By combining large language models, sequential recommendation systems, and real-time infrastructure, LinkedIn is building a platform capable of interpreting professional context at unprecedented scale.
When the next highly relevant post appears in your Feed – perhaps written by someone outside your network but discussing exactly the topic you care about – it may feel intuitive. Behind the scenes, however, that moment is the result of AI systems analyzing millions of interactions and continuously mapping the evolving landscape of professional knowledge.
The Linked Blog is here to help you or your brand have the best possible LinkedIn presence, so feel free to contact us if you need help! See more about what we can do for you here.


